
欢迎来到合肥浪讯网络科技有限公司官网
 咨询服务热线:400-099-8848
咨询服务热线:400-099-8848
咨询服务热线:400-099-8848
咨询服务热线:400-099-8848
机器学习在股票猜测范畴的探究与实践 |
| 发布时间:2025-11-07 文章来源:本站 浏览次数:1246 |
机器学习在股票预测领域的应用发展非常迅速,最新的研究在模型架构、关系学习以及技术集成等方面都取得了显著突破。机器学习在股票猜测范畴,仍存在一些尚未彻底霸占的难题。虽然如此,因为该范畴潜在的巨大收益,相关研讨一直在继续推动。出资者巴望能安心地将资金投入体现出色的公司,如此一来,跟着出资增多,公司有望快速发展,出资收益也会相应增加。 回忆过往研讨,虽已涌现出诸多方法,但成效并不显著。因而,本文测验将研讨范畴拓宽至GANs范畴,探究其在股票猜测方面的可行性。 kaggle中的JPX市场猜测数据集固然优质,然而其猜测与提交需在kaggle平台进行。所以,本文选用其一个子集,并针对特定测验指标打开测验,以此呈现此次研讨的真实成效。 在正式开启研讨前,咱们将为一切模型一致实施相同的预处理方法与评分指标。先从预期功能欠佳的线性回归基线模型着手,将其设为小基线。随后,对XGBoost模型和CAT boost模型进行优化,并将这两个模型叠加(复现竞赛中排名靠前的模型),力求完结超越佳模型的体现。在此之后,深化探究GANs解决方案,观察其能到达的作用。 数据集将被区分为曩昔的练习数据与近期的测验数据。在数据提取和特征工程进程中,一直保持这一区分,以根绝数据泄露问题。咱们将选用夏普比率,这是一种在人力资源管理与人力出资策略评分中广泛使用的指标。夏普比率由诺贝尔奖得主威廉・F・夏普提出,旨在助力出资者明晰出资报答与危险的比例。该比率指的是每单位波动率或总危险超出无危险率的均匀收益。波动率用于衡量资产或出资组合的价格波动状况。夏普比率会根据出资者承当的超量危险,对出资组合的过往体现或未来预期体现进行调整。相较于报答率较低的相似出资组合或基金,较高的夏普比率无疑更为理想。不过,夏普比率也存在一些局限性,比如假定出资报答呈正态散布,在此暂不打开胪陈。 数据预处理与特征工程在金融技术分析范畴,技术指标是基于前史价格、交易量或证券及合同未平仓量的数学核算或模式信号,借助调和指标可以猜测金融市场走势。关于数据科学家而言,这便是所谓的特征工程。本项目选取某范畴专家提出的顶级技术指标作为特征,如7天和21天的移动均匀线、指数移动均匀线、对数动量、布林带和MACD等。傅里叶变换是处理时刻序列数据的常用手法,它能按捺数据中的计算反常,而且已证明可助力gru(使用于咱们的GANs模型)学习更为稳健的模式。 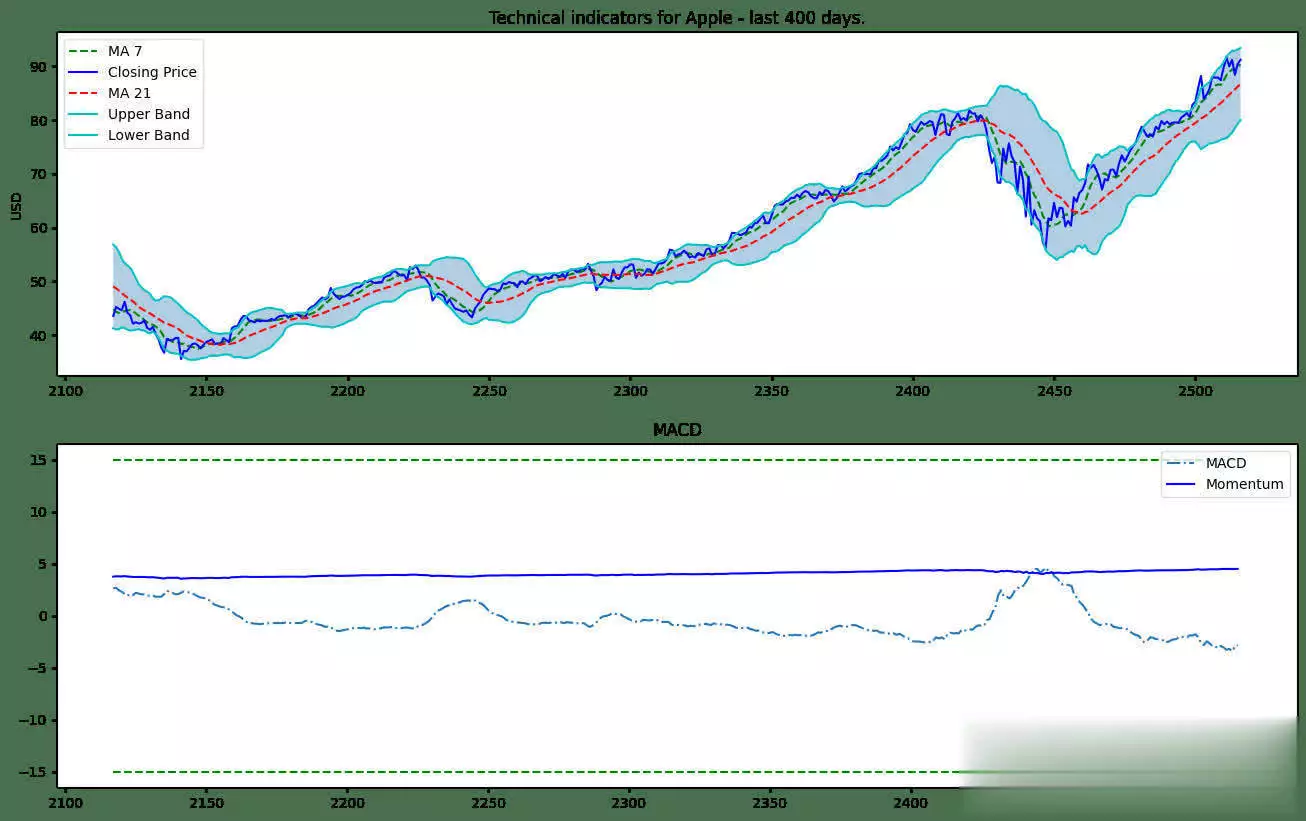 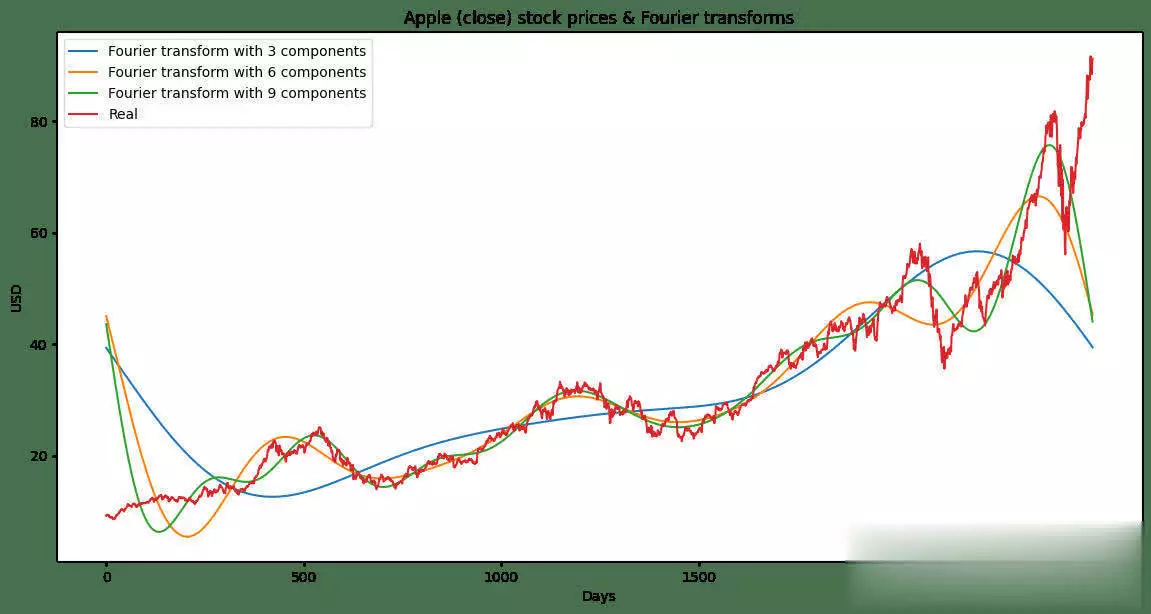 咱们的方针猜测值为股票收盘价。从上述图表来看,很难直观判断曩昔的数据能否有用猜测未来数据。但当运用自相关进行计算分析(自相关指的是同一变量在两个接连时刻距离之间的相关程度,用于衡量一个变量值的滞后版别与其在时刻序列中的原始版别之间的关系),选用滞后参数100时,得到了较强的正相关,这意味着咱们的猜测模型有望收获良好作用: 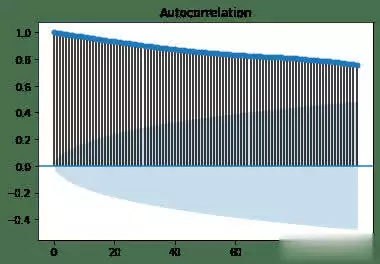 完结一切预处理后,便可以着手练习不同模型并得出相应成果。 线性回归咱们的线性回归模型验证夏普比率为0.44,接近Numerai文章所到达的方针0.49。关于一切这些模型,咱们将数据区分为练习集与测验集,并根据特定日期股票市场的技术指标,来断定次日股票市场的收盘价。 超参数调整算法咱们选用一种定制的二进制搜索算法,它可以快速搜索超参数值的或许空间。结合手艺模型调优的经历,咱们以为这种算法比选用暴力搜索一切超参数组合(如典型的网格搜索)能获得更优成果。这使咱们可以对规划加以改善,并在测验中敏捷调整方向。 XGBoost关于XGBoost模型,咱们发现增加超参数可使其到达佳功能。初始XGBoost的夏普得分仅为0.71,而优化超参数后,该模型的夏普得分提升至0.78。 CAT Boost就CAT Boost模型而言,咱们观察到其功能优于参数化CAT Boost模型,夏普得分高可达0.90,而Numerai文章中的数值为0.87。 堆叠模型将超参数化的XGBoost模型与普通的CAT boost模型叠加,可以收获佳作用。咱们得到的分数为0.946,接近文章中的0.934。该模型的运作原理是取两个模型猜测值的均匀值。 GANs1、什么是GAN 生成对立网络,简称GANs,是一种运用深度学习进行生成建模的方法。它将生成新数据的非监督问题转化为监督问题,在此监督问题中,模型根据成果的可信度进行评分。GAN系统由鉴别器与生成器两个子模块构成。鉴别器在学习进程中会接收两类图画,即真实图画与虚伪图画,其职责是学会区分二者,并为生成器提供相关信息,以生成更为传神的输出。 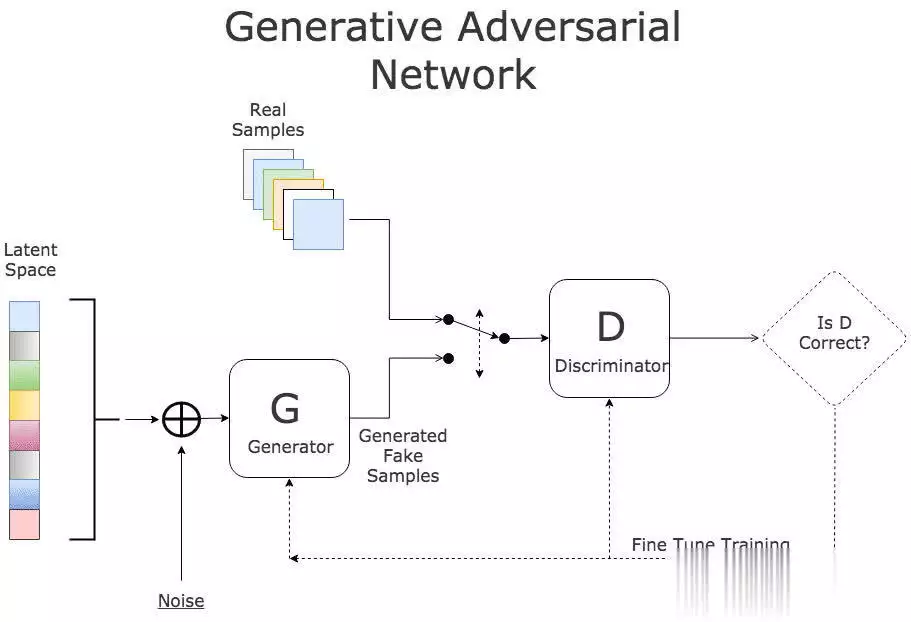 咱们期望鉴别器可以出色履行职责,但又不能过于完美,因为若鉴别器过于强大,生成器无论怎样学习都无法骗过它。为到达这一方针,咱们必须规划一个架构优秀的强健网络。 2、WGAN - GP的改善 Wasserstein Gan +梯度赏罚,即WGAN - GP,是一种生成对立网络,它借助Wasserstein丢失以及梯度赏罚来完结Lipschitz接连性。这两者的结合旨在克服以往模型的缺陷。 Wasserstein距离(也称作Earth Mover距离)是给定衡量空间上两个概率散布之间的距离衡量,可以理解为将一个散布转变为另一个散布所需的小工作量。它处处可微,可以使练习模型到达佳功能,而且满足安稳,可防止练习崩溃(若鉴别器饱满且过于强大,梯度将降至零,导致无法收敛。WGAN在安稳GAN练习方面获得了一定发展,但有时仍或许仅生成低质量样本或无法收敛)。因而,增加梯度赏罚,这种丢失函数可将梯度限制在一定范围内,防止或许呈现的梯度消失或梯度爆炸问题。 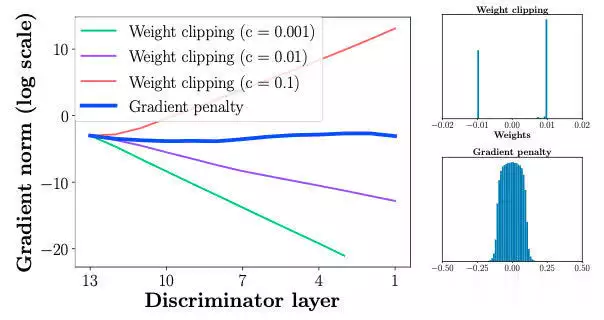 引进GP是对这种剪切方法的代替,它对输入的梯度进行赏罚,而且可与一切架构交融,只需进行少量超参数调优,就能让练习成果更加安稳。 增加GRU为进一步优化模型,咱们期望学习相似LSTM的方法,以某种途径捕捉学习进程中的时刻特征。GRU可作为常规卷积的代替方案,以更为简练的规划完结LSTM的大部分优势。GRU由一个重置门和更新门构成,可视为LSTM的简化版别。 WGAN - GP怎么使用在股票猜测咱们运用WGAN - GP对上述预处理后的数据进行练习,得到以下成果: 1000.00usd =(End Portfolio:5327.83USD,Sharpe:0.819) 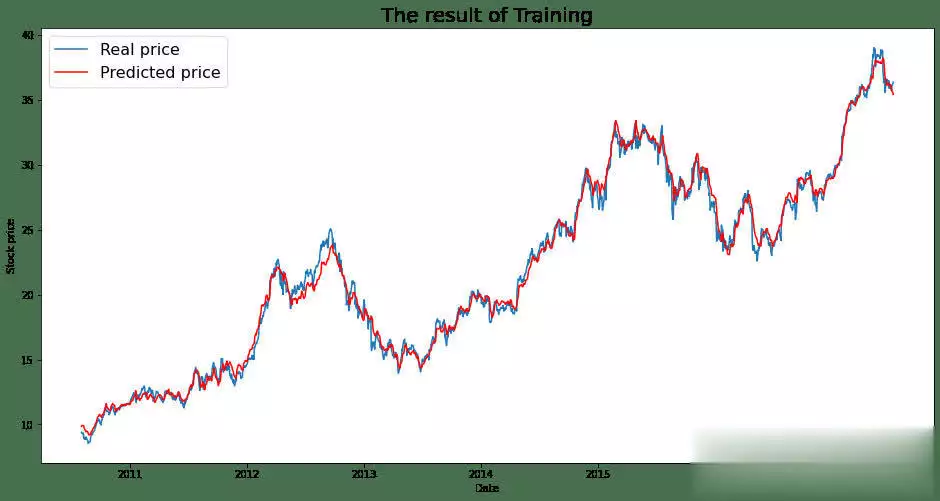 通过1000次迭代后,成果看似不错。然而,当咱们测验对一组彻底不知道的未来数据进行验证时,却得到了以下成果: 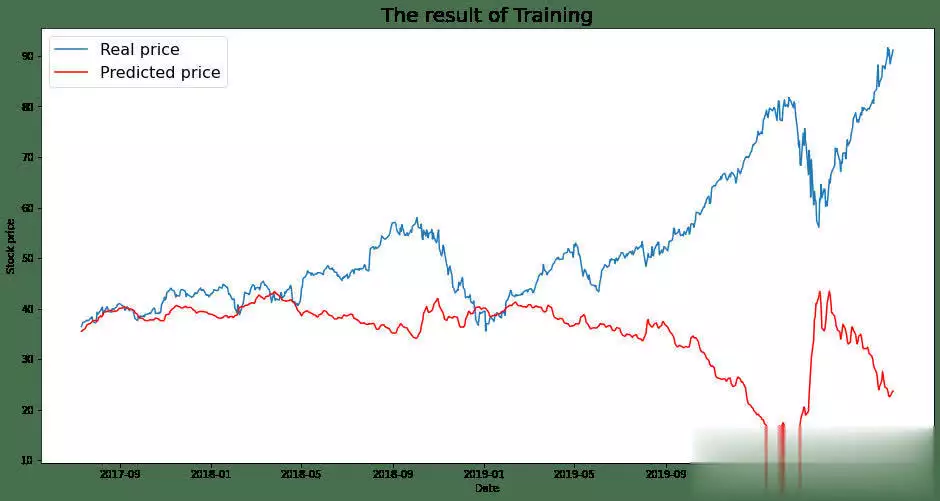 这是否意味着该模型不可行呢?并非彻底如此,原因或许如下。在回忆其他通常运用回归或lstm的相似研讨时,有几篇论文将COVID时期视为数据中的反常状况,因其史无前例的特殊性,他们选用了一种简略的处理方法,即扫除该反常周期,但这种做法被以为只是在掩盖问题。因而,我并不计划选用这种方法。 实际上,这里呈现的状况是,未来数据超出了当时模型的猜测范围,因为它超出了以往所见的任何数据边界。若观察练习数据,会发现价格从未超过40USD。也就是说,咱们并未对猜测价格进行归一化处理,所以咱们将数据从USD转换为[-1,1]之间的缩放值。 看看这一假定与校对是否能发生更好的成果: 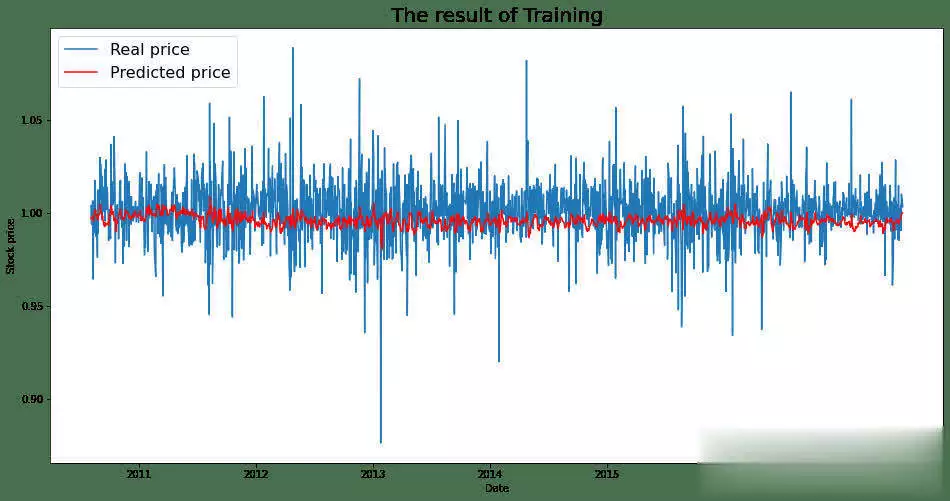 显然,这是一个糟糕的成果,在此将其作为测验失利的记载。 运用window我从头审视了核心假定,意识到练习方法与测验模型的方法存在差异。练习时的输入具有特定窗口,而测验时并未运用这一前史窗口。所以,我修改了测验代码,增加了该窗口,终究得到以下成果: 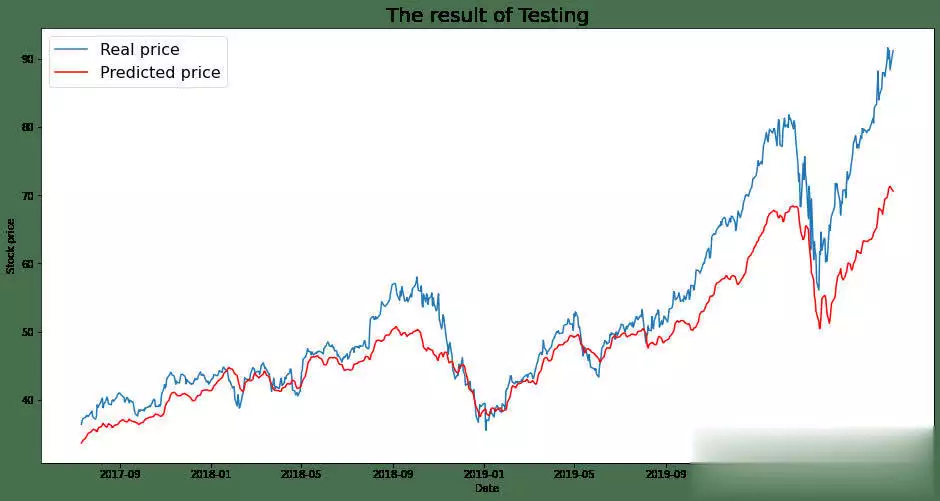 可以看出,现在的猜测趋势彻底正确,但猜测粒度显着较低。这是因为在确认有用策略时练习缺乏所致。从500次到5000次迭代,在测验会集发生了以下成果: 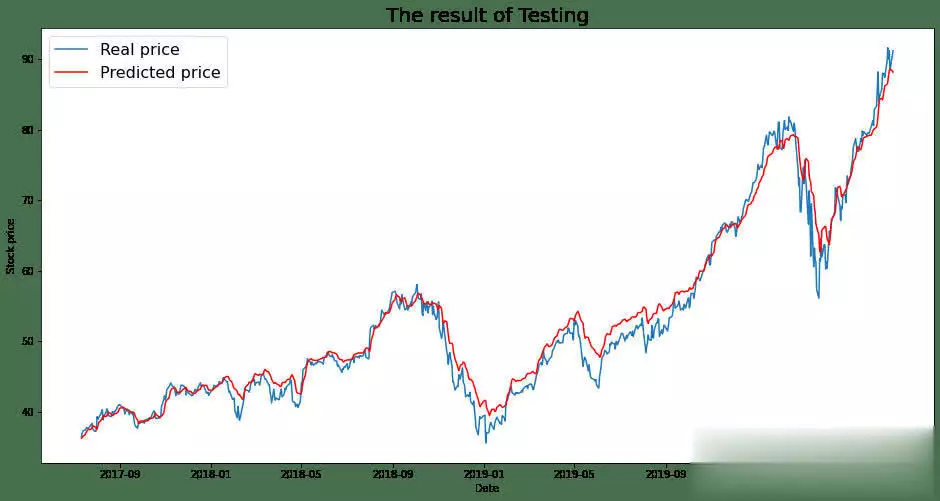 可以发现,在恰当长的一段时刻内,咱们的模型在彻底不知道的数据上体现近乎完美。模型可以在2017 - 07 - 12至2018 - 02 - 08(146天)期间,将1000.00美元转化为1181.15美元,市盈率为1.52。虽然跟着时刻推移,模型在某些地方会呈现偏差,但因为模型每月甚至每晚都可根据新数据和新趋势进行继续再练习,在第二天开业前就能完结猜测。 总结
GANs网络不仅在图画处理范畴展现出潜力,在金融和股票猜测范畴同样远景可观。通过更多的调优以及对猜测进行恰当格式化处理,这些GANs的成果可与功能优秀的回归器叠加,以完结更优、更具弹性的猜测。此外,还能提取整个网络的学习潜在空间,并将其作为回归模型的特征输入。总体而言,这些实验成果充满希望,为该使用的进一步复杂改善奠定了根底。 |


